Moderation Architecture
The system has two layers:
- Preventive moderation
- Enforcement system
The first layer checks content before publication.
The second layer handles reports, user actions, and moderation decisions.
Preventive Moderation
The moderation flow:
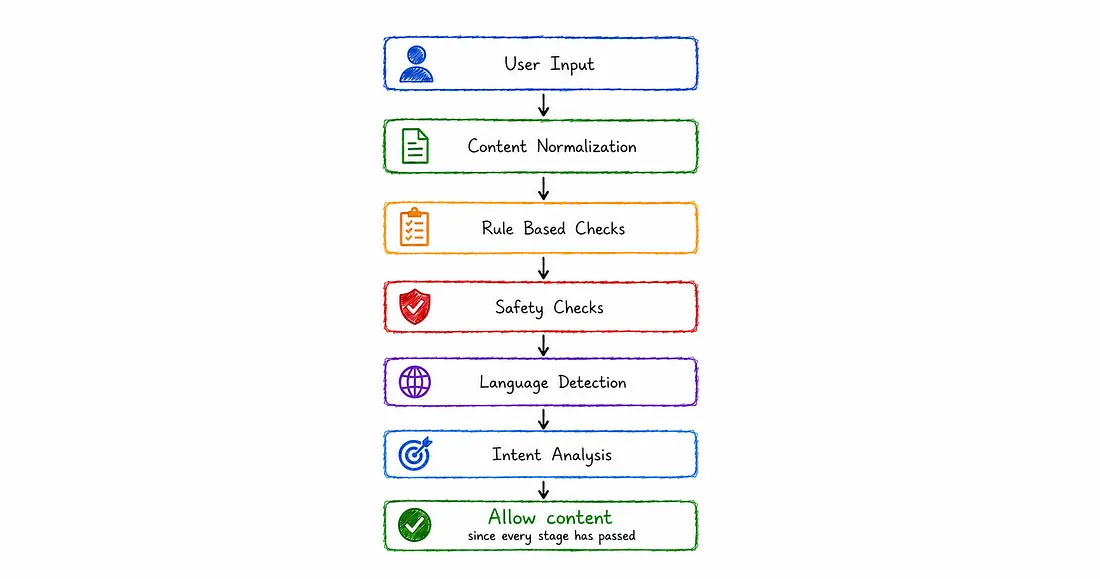
Each stage handles a specific problem.
Content Normalization
Users often try to bypass moderation.
Examples:
banned words with spaces
special characters
different casing
Before running checks, content gets normalized.
This gives every moderation step a consistent input format.
Rule Based Moderation
Some checks do not need machine learning.
Rules work well for predictable cases.
Examples:
- banned words
- custom community rules
- restricted phrases
Flick stores these rules separately and lets administrators update them through the admin panel.
This keeps moderation changes separate from application code.
Real-Time Text Moderation
Real-time moderation has performance challenges.
I covered the implementation details in my previous article:
Designing Real-Time Text Moderation Without Freezing the Browser
The article covers:
- handling moderation while typing
- reducing browser workload
- optimizing text checks
- balancing user experience with security
This article focuses on the larger moderation system around those checks.
Self Harm Detection
Toxic content is one category.
Self harm content needs different handling.
The system checks for self harm related signals before publishing.
This gives the platform a separate path for these cases.
Language Detection
Language detection helps support multilingual content.
The detected language helps with:
- future model improvements
- language specific rules
- better moderation accuracy
Intent Based Toxicity Detection
Keyword filters have limits.
A harmful message does not always contain a banned word.
Example:
"Nobody wants you here."
A word filter might miss this.
The system uses a toxicity classification model to detect harmful intent.
The model checks patterns related to:
- harassment
- insults
- toxic behavior
- abusive language
Moving From External APIs to Self Hosted Models
During development, I researched external moderation APIs.
I first used Perspective API because it matched my requirements.
Later, the service was discontinued.
This changed my approach.
I moved toward running my own model.
I used a Detoxify based model and optimized inference with ONNX runtime.
The goal was simple:
Run moderation locally with fewer external dependencies.
Reducing Repeated Model Processing
Machine learning inference costs more than normal text checks.
The same content does not need repeated evaluation.
The system stores moderation results and reuses them when the same content appears again.
The flow:
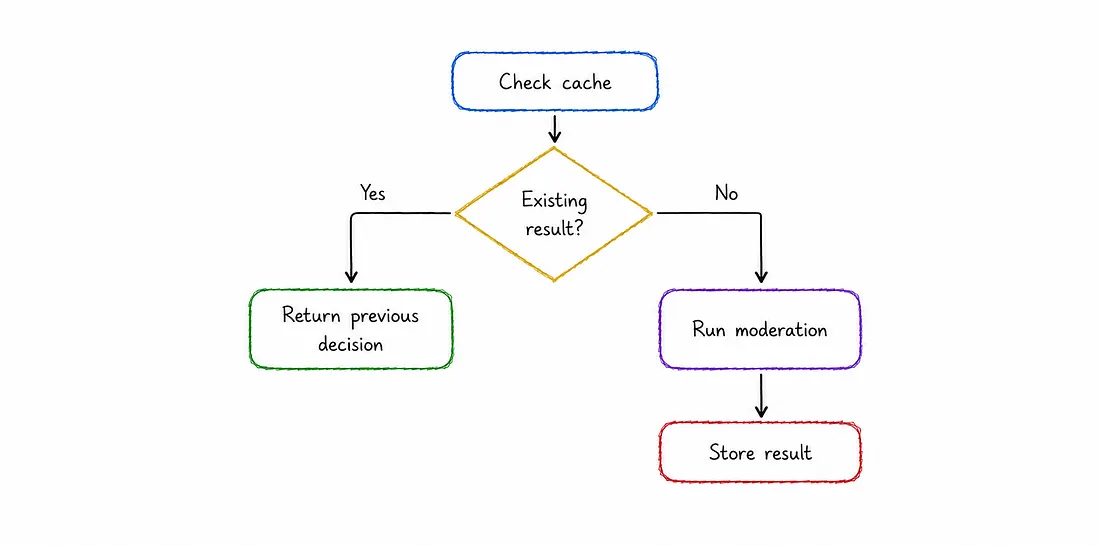
This reduces repeated processing and improves response time.
Enforcement Layer
Preventive checks will miss some cases.
Users need reporting tools and safety controls.
The enforcement layer handles actions after publication.
Content Reports
Users report content they find harmful.
The admin panel provides tools to review reports and take action.
Actions include:
- removing content
- banning users
- suspending accounts
- shadow banning content
Shadow Banning
Some users repeatedly abuse the platform.
Immediate deletion is not always the first step.
Shadow banning reduces visibility while keeping the account active.
The user sees their activity, while other users do not.
User Blocking
Moderation also happens at the user level.
Users need control over their own experience.
Flick supports blocking users to prevent unwanted interactions.
Challenges
Moderation systems have tradeoffs.
False positives:
Good content gets blocked.
False negatives:
Harmful content gets through.
Latency:
More checks increase processing time.
Maintenance:
Rules and models need continuous updates.
Future Improvements
The next improvements I want to explore:
- moderation queues
- confidence scores
- user trust scores
- better moderation analytics
- automated review workflows
Building moderation for an anonymous platform taught me one thing.
Moderation is a system of multiple checks.
Rules handle predictable cases.
Models handle intent.
Reports handle edge cases.
Together, these layers create a safer platform.