Context: This is the auth system I built for Flick. Over ~9–10 months, I iterated on it multiple times and learned a lot — mostly by getting things wrong first.
Anonymous ≠ Secure: What I Got Wrong About Identity Design
I built an anonymous auth system, broke it multiple times, and learned why identity isn’t something you can just remove.
Phase 1: Optimizing for the Wrong Problem
When I started building Flick, my first thought was simple: anonymity with security.
Because when I posted about Flick on Reddit, someone called out about db leak and anonymity problems.
So I assumed that even if the database leaked, no one should be able to map users to real identities. so I dropped email from the core identity and treated it as just a registration thing.
That decision started haunting me pretty quickly.
- OTP verification needed something stable
- login didn’t make sense (no one’s logging in with a random UUID username)
- banning or suspending users? almost impossible without some form of identity
I had basically removed identity without thinking about how the system would actually run.
At that point, I doubled down on security. I went deep into hashing, encryption, encoding — bcrypt vs crypto, RSA, SHA256, all that. I thought if I just made the data strong enough, the system would be safe.
But honestly, I was solving the wrong problem. Stronger cryptography didn’t fix anything. It just made an already broken design harder to reason about.
The real issue was this:
I assumed anonymity automatically makes a system secure.
It doesn’t.
All I had done was remove identity — without understanding why the system actually needs it in the first place.
Phase 2: Patching a Broken System
After trying a bunch of workarounds (most of them not great), I landed on a kind of “compromise”.
Instead of removing email completely, I:
- hashed it for lookup
- encrypted it for OTP
The idea was simple, hashed for querying, encrypted for reversibility when needed.
On paper, this felt like I was solving both problems (security and usability). In reality, I had just split identity into two different representations.
I also added middleware to make sure email was never exposed to the client side (didn’t know about DTOs back then, so this was my version of it).
Eventually, I got an auth system working.
Flow (simplified)
Initialization
- Validate input
- Validate email (regex… don’t judge) + disposable email check
- Hash + encrypt email
- Send OTP
- Store temporary user data in cache (keyed by hashed email)
Registration
- Send raw email → hash it
- Fetch cached data
- Create user
- Set cookies + clear cache
This allowed me to verify email before creating a DB entry, which felt like a clean approach at the time.
But looking back, this is where things started getting messy.
What was actually wrong
- I split identity across hashing + encryption → more complexity without actually improving security
- Temporary user data in cache (without any session) → easy attack surface if not handled carefully
- Separate admin/user flows → duplication for no real gain
- Large, tightly coupled files (500–600 LOC controllers) → hard to reason about
- MVC without proper separation → logic leaking everywhere
Basically, I had patched the system instead of fixing the design.
It worked… but I didn’t trust it.
And more importantly, I still hadn’t solved the original problem — I was just making the system harder to understand while thinking it was “more secure”.
Phase 3: Rethinking the System
After a few months of doing backend more seriously (and during my internship), I learned a lot of things I completely ignored earlier.
So I decided to refactor the whole codebase. While doing that, I revisited the auth system — and yeah, it was worse than I remembered.
It wasn’t just messy. It was fundamentally flawed.
At that point, I stopped trying to “fix” it and decided to rethink the whole thing properly.
What I changed (and why)
I moved to:
- BetterAuth → I kept running into edge cases around sessions and verification, and fixing one thing was breaking something else
- PostgreSQL → Mongo started breaking down once identity relationships got even slightly complex (those aggregation pipelines were getting out of hand)
- Modular architecture → earlier everything was tightly coupled, controllers doing too much, logic everywhere
I redesigned the workflow again. Now it had:
- RBAC with unified auth workflow → earlier I had separate flows with small differences, which just created duplication
- Session management handled by BetterAuth → stopped juggling identifiers and let sessions be the source of truth
- SignupId as a temporary identifier → instead of abusing email/cache as identity
- Cached data is about profile, not identity → this was a big shift from my earlier design
- Multi-step email verification → disposable + domain checks + banning → more control before user even enters system
- Auth and User as separate schemas → identity vs profile finally made explicit
- Never sending auth data to client → something I was careless about earlier
- Better edge case handling → because I had already hit most of them the hard way
What the system looks like now
At a high level, the flow now looks like this:
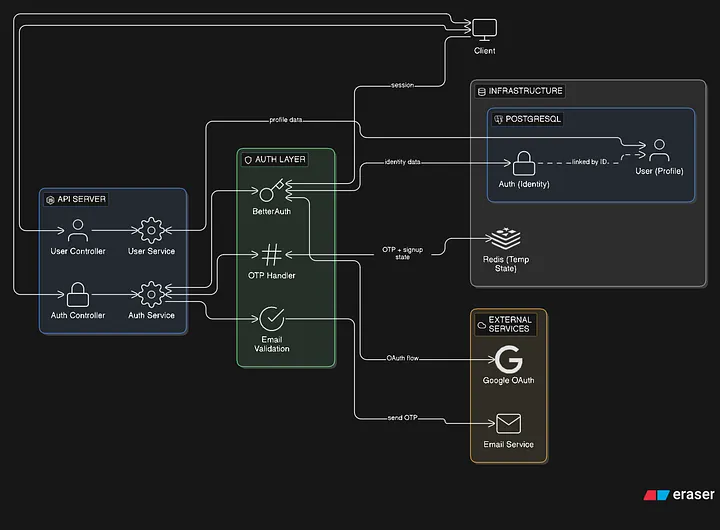
Registration flow:
- user starts registration → temporary signupId is created
- email goes through validation (student domain + disposable checks)
- OTP is sent and verified (with attempt limits and expiry)
- until verification, everything stays in cache — nothing touches the database
- once verified → auth record is created via BetterAuth
- then a separate user profile is created and linked to it
Login is mostly handled by BetterAuth now:
- email/password → direct sessionClosing Thought
I started by trying to hide identity completely. and ended up learning that identity is unavoidable.
The real challenge is:
deciding what should be hidden, what should be traceable, and where to draw that boundary.
- OTP login → verify → create session
- OAuth → same idea, just a different entry point
Nothing here is fancy. The steps are pretty standard.
What actually changed is how things are separated.
If you want the full detailed flow (endpoints, caching, edge cases, all that), I’ve documented it here: Link to docs
What actually improved
- identity and profile are completely separate (auth vs user)
- sensitive data like email never leaves the auth layer
- temporary state (signup, OTP) lives in cache, not in the database
- sessions are the source of truth instead of juggling identifiers
Earlier, I was trying to remove identity completely. Now I just control where it exists — and where it doesn’t.
What Changed (The Real Insight)
The biggest shift wasn’t tools or architecture.
It was this:
I stopped trying to eliminate identity and started controlling how it’s used and exposed.
Anonymity doesn’t remove identity. It just changes how carefully you need to handle it.
What This System Still Gets Wrong
This isn’t perfect.
- Redis is not great for storing temp data like this, would be better if moved to db
- Email is still a weak identity anchor
- Correlation risks can still exist in edge cases
- More security → more complexity → harder to reason about
- Tradeoff between anonymity and moderation is always there
Closing Thought
I started by trying to hide identity completely. What I learned is that identity isn’t optional.
The real challenge is controlling where it exists, and how much it can expose when things go wrong.
Related content
When Google Killed My Moderation API, I Had to Rebuild the Entire Stack
(software-engineering)I was building an anonymous platform, so moderation wasn’t optional.
Designing Real-Time Text Moderation Without Freezing the Browser
(software-engineering)How I built real-time text moderation for an anonymous platform without freezing the browser or trusting the client.
Redis Streams vs Kafka: When to Use What
(distributed-systems)A practical comparison of Redis Streams and Kafka through the lens of real engineering tradeoffs.